 |
forums.silverfrost.com
Welcome to the Silverfrost forums
|
| View previous topic :: View next topic |
| Author |
Message |
mecej4
Joined: 31 Oct 2006
Posts: 1925
|
 Posted: Thu Oct 13, 2022 3:04 pm Post subject: Inefficient processing of expressions with SPREAD intrinsic Posted: Thu Oct 13, 2022 3:04 pm Post subject: Inefficient processing of expressions with SPREAD intrinsic |
 |
|
While revamping and modernizing the Netlib Odepack package, we ran into an astounding slowdown when the code was compiled with FTN95 8.91. The code contains two blocks of code in which the SPREAD intrinsic is used. The first instance is
| Code: |
#ifdef SPREAD
allocate (d1v(l-1))
do j = 1, l - 1
r = r*rh
d1v(j) = r
end do
yh(:n,2:l) = yh(:n,2:l)*spread(d1v,dim = 1,ncopies = n)
deallocate (d1v)
#else
do j = 2,l
r = r*rh
do i = 1,n
yh(i,j) = yh(i,j)*r
end do
end do
#endif |
and it should be noted that the second alternative (following the "#else") is the F77 way, using double loops. This instance of SPREAD did not cause any noticeable slowdowns when the code was compiled with FTN95.
The second instance involves the product of two SPREADs:
| Code: |
#ifdef SPREAD
yh(:n,:l) = yh(:n,:l) + spread(el(:l),dim = 1,ncopies = n) &
* spread(acor(:n),dim = 2,ncopies = l)
#else
do j = 1,l
do i = 1,n
yh(i,j) = yh(i,j) + el(j)*acor(i)
end do
end do
#endif |
Here are some timing results.
| Code: |
Internal timing Shell timing
WITH WITHOUT WITH WITHOUT (-D SPREAD)
COMPILER
LF 0.062 0.047 0.105 0.096
GF 0.046 0.047 0.116 0.142
SF64 8.469 0.094 8.606 0.221
SF32 41.047 0.109 41.134 0.177
ABS64 0.063 0.047 0.124 0.131
ABS32 0.114 0.063 0.129 0.137
LF: Lahey 7.1; GF: Gfortran 11.3; SF64: FTN95 /64; SF32: FTN95
|
Note the tremendous slowdown shown for SF64 and SF32 in the second column; the use of SPREAD slowed down the code by a factor of 400!
There was an extensive discussion in 2018 of the FTN95 implementation of SPREAD [url] http://forums.silverfrost.com/viewtopic.php?t=3822[/url] in this forum, at the end of which Paul wrote, "My understanding of this issue differs from yours. I will take another look at it when I get a moment."
The source code and batch files to build and reproduce the problem are available at https://www.dropbox.com/s/y0n4r22ioyr7y96/lsodpk.zip?dl=0 .
It should be noted that neither instance of SPREAD involves any matrix multiplication. Readers unused to SPREAD may look at the F77 versions of the code blocks, and note that for the yh array of size M X N there is a need for just M X N multiplications in the first block. In the second block, the need is for M X N multiplications and M X N additions. In neither instance does SPREAD occur inside any loop, so each run through the subroutine containing the code should require only three evaluations of SPREAD.
I am curious to know, in addition: does anyone use SPREAD frequently? I do not, myself, and it was code polishing software that inserted it. It did take some investigation to track the slowdown to SPREAD. |
|
| Back to top |
|
 |
PaulLaidler
Site Admin
Joined: 21 Feb 2005
Posts: 8302
Location: Salford, UK
|
| Posted: Thu Oct 13, 2022 5:17 pm Post subject: |
|
|
mecej4
Many thanks for the feedback.
I can see that the FTN95 optimiser does not work well in this context. Presumably SPREAD is called multiple times when it needs to be called only once and maybe there is also an unnecessary "copy in" and/or "copy out" when performing the matrix product.
Clearly this code change produced by the "code polishing software" does not help when using FTN95. |
|
| Back to top |
|
|
LitusSaxonicum
Joined: 23 Aug 2005
Posts: 2431
Location: Yateley, Hants, UK
|
| Posted: Thu Oct 13, 2022 8:34 pm Post subject: |
|
|
On the one occasion I used code polishing software (CPS), the output was, to my eyes, far less comprehensible than the original. The style you get is what the author of the CPS thinks is ideal. At least I could understand the original sometimes I see Fortran codes that are incomprehensible in the first place.
Mecej4, you may know the adage that there is something that you cant polish. |
|
| Back to top |
|
|
DanRRight
Joined: 10 Mar 2008
Posts: 2952
Location: South Pole, Antarctica
|
| Posted: Fri Oct 14, 2022 10:08 pm Post subject: |
|
|
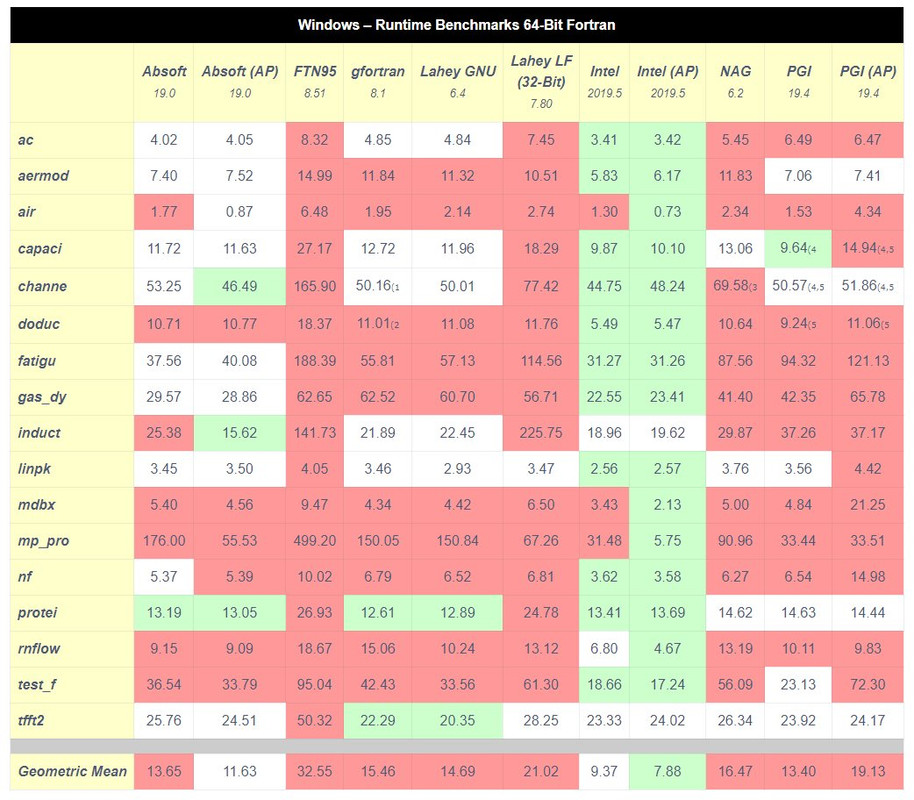
I know we all have a lot of problems and little-to-zero free time for anything but Silverfrost definitely has to squeeze some extra time and resources to fix the speed issue in the way too many other cases. Polyhedron tests just show the magnitude of a disaster. Up to 86x slower in some cases (see mp_pro run speed below). Last in the charts and again amazingly users and developers are ok with that. This hurts the company itself. All other developers improved the speed long ago.
I was ok with FTN95 because i used external parallel libraries from the year ~2000 when multicore processors appeared and due to that did not experience its slowness. But how come other fortraneers do not care about speed? We are talking about these Polyhedron tests since ~1997. Only John Campbell cares about speed and due to that moved to gFortran? Unbelievable world we are living in today. It's like a Matrix.
Looks like somebody need to help Silverfrost to start with this. Someone with Assembler knowledge. For example, Mecej4, can you look at these tests and by placing high resolution timer into these Polyhedron tests try to find the critical spot of the source codes causing slowness? And since you also know assembler and can use other compilers, you probably can give an educated guess what's wrong. Silverfrost probably can then issue FTN95 Pro version only for subscribers and for you for free!
I remember John Campbell years ago also spent time running these tests.
 |
|
| Back to top |
|
|
mecej4
Joined: 31 Oct 2006
Posts: 1925
|
| Posted: Sat Oct 15, 2022 12:32 pm Post subject: |
|
|
Dan, let me try to persuade you that we should not ask for the FTN95 compiler, all by itself, to deliver the performance improvements that all of us users want.
It is unrealistic to expect that FTN95 can match the performance that we can obtain by compiling with Intel Fortran, Flang, Gfortran, etc., unless we are willing to give up the fast compilation, excellent error checking and debugging facilities, and graphics features that attract us to FTN95.
There is a part for us, the users, to play. Every few years, we need to ask if we need to modernise our existing programs by using newer Fortran language features, software libraries and programming techniques that are better matched to the microprocessor architectures that we currently use, etc.
Take the Polyhedron Linpack benchmark, for example. It solves a dense system of 2500 linear equations. It does so using the excellent but obsolete DGEFA and DGESL routines from the excellent but obsolete Linpack package. The Polyhedron benchmark results for it ( https://polyhedron.com/?page_id=175 ) show that the slowest is no worse than twice as slow as the fastest, so it is easy to conclude that there is not much to be done improving the performance of FTN95 on that benchmark.
Please take the following modernised version of the Linpack benchmark program, compile it with FTN95 and link with either OpenBLAS ( https://github.com/xianyi/OpenBLAS/releases/download/v0.3.21/OpenBLAS-0.3.21-x64.zip ) or Intel MKL . Time the resulting program and come back here to continue the discussion.
| Code: |
PROGRAM LINPK
!
! Same calculation as is present in old Linpack Benchmark, converted
! to using Lapack and BLAS
!
implicit none
DOUBLE PRECISION, allocatable :: A(:,:), Asav(:,:), b(:) , x(:)
DOUBLE PRECISION norma , normx
DOUBLE PRECISION resid , residn , eps
INTEGER, allocatable :: ipvt(:)
integer :: N, info,i
!
! Allocate arrays
!
N = 2500
allocate(A(N,N), Asav(N,N), B(N), X(N), IPVT(N))
!
! Create matrix with elements between -1.0 and +1.0
!
CALL Random_Number(A)
A = 2*A - 1
norma = 1d0
Asav = A
b = sum(A,dim=2)
!
! matrix factorization
!
call DGETRF(N,N,A,N,IPVT,info)
x = b
!
! obtain solution to linear system using factorized matrix
!
call DGETRS('N',N,1,A,N,IPVT,X,N,info)
!
! compute residual vector
!
CALL DGEMV('N',N,N,1d0,Asav,N,X,1,-1d0,b,1)
!
! compute norms of residue, b, x, scale
!
resid = maxval(abs(b))
normx = maxval(abs(x))
eps = EPSILON(1.0D0)
residn = resid/(N*norma*normx*eps)
WRITE (*,200)
200 FORMAT (' norm. resid resid machep', &
& ' x(1) x(n)')
WRITE (*,300) residn , resid , eps , x(1) , x(N)
300 FORMAT (1P5d16.8)
deallocate(A, Asav, B, X, Ipvt)
END |
|
|
| Back to top |
|
|
DanRRight
Joined: 10 Mar 2008
Posts: 2952
Location: South Pole, Antarctica
|
| Posted: Sat Oct 15, 2022 8:59 pm Post subject: |
|
|
Mecej4,
We already have done a lot of benchmarking with you using MKL. What are you trying to add to discussion with this foreign libraries? They have no relationship to FTN95.
I am surprised you mentioned fast compilation will suffer if Silverfrost would optimize the compiler for speed. Just do not use /optimize.
If you are masochistic and need slower code do not use /parallel or /O3 with Intel Fortran AP which automatically parallelizes and heavily optimizes
I was forced last year to use gFortran and Intel Fortran and surprisingly found that their compilation speed is as fast as FTN95 if you use MAKE and do not use level 3 optimization and even with optimization it's acceptable. This is because in most of frequent recompilations when you heavily develop code MAKE does not recompile the entire code, in most cases it recompiles one file, and this is done automatically you do not have to chose files to re-compile (hopefully Plato is doing that too but i do not use Plato, i recompile with the batch files. My batch files with FTN95 also can compile individual files for additional speed in addition to many other situations like nocheck, undef, full_debug, opt etc )
In short, on the solely Fortran language side the FTN77/95 was leader in 1990 in features. Since that time all lagers improved a LOT, specifically last decade, and FTN95 now lags in this respect by decades. Lags by huge margin in speed and features.
FTN95 is still a leader with Fortran95 diagnostics but even this leadership in some cases narrowed to zero. Will repeat that as to the 2003/2008/2018 features and parallelization FTN95 need and very quickly some extra efforts to catch the crowd. Because i afraid due to not so many users with FTN95, cleaning all the bugs and make the execution fast and rock stable after implementing them will also take 1-2 decades like it was with Fortran 90/95 after FTN77 ( I tried to use Fortran-90 features several times after 1997 and failed due to terrible crashes all the time. Same even happened with TYPE features of Fortran-90 just 3-4 years ago ).
I am not trying to diminish FTN95, it is and will be my #1 compiler. Nothing is better for the code development and debugging and that is the major part of time and money loss not the speed per se. I will tell even more - using many new features of 2003/2008 will make your code worse, and sometimes totally unreadable and simple things hidden, modifications of code a nightmare, bug-ridden and even slow. But soon i will be not able not use it if there is no some new and really important Fortran features and clearly becoming de-facto standard ways of parallelization. If this compiler will stay only with Windows, it will miss the boat when Linux OS finally became useful and user-friendly, thanks to mobile revolution, and parallel calculations soon will be in very many programs. In not so distant future we will see merge computers and supercomputers thanks to numerical simulations on graphics processors will be more and more common. All supercomputers now have graphics processors as a major boost of performance. Where is FTN95 respect to supporting CUDA? There will be no single power user with FTN95 if it will not support Linux, Fortran2003/2008, OpenMP, MPI and CUDA.
Admittedly, these power users are small part of users, most people still use Fortran90 and even Fortran77 but exactly these freaks make these tables like Polyhedron everyone reads when choosing compilers where FTN95 either lags in speed or totally missing in features. My criticism will not move a single person not to buy this or that compiler, it is impossible to convince anyone in anything. But we need such users telling others that they recommend Silverfrost compiler in their websites and advertisements otherwise we all users and developers will suffer.
I also have mentioned graphics way of doing diagnostics report when the error is not told but shown. This would be nice addition for people who are not frequent with English (most world programmers right now).
Last edited by DanRRight on Sun Oct 16, 2022 6:50 am; edited 3 times in total |
|
| Back to top |
|
|
DanRRight
Joined: 10 Mar 2008
Posts: 2952
Location: South Pole, Antarctica
|
| Posted: Sun Oct 16, 2022 1:40 am Post subject: |
|
|
I guarantee that this table above flashing such results for 20 years made that FTN95 lost 10 times of its currents users base. And this was the most credible site which was testing speeds and features of all Fortran compilers and also recommending and selling them. I was buying things from them. Good that i bought it before these tests were published  |
|
| Back to top |
|
|
PaulLaidler
Site Admin
Joined: 21 Feb 2005
Posts: 8302
Location: Salford, UK
|
| Posted: Sun Oct 16, 2022 8:33 am Post subject: |
|
|
Dan
Thank you for promoting FTN95 with it is and will be my #1 compiler.
Apart from that your post includes a number of false or unsupported statements that IMO are not helpful.
In my experience...
1. FTN95 is a great deal faster at compilation than Intel or gFortran.
2. FTN95 has the best compile time and runtime diagnostics.
3. FTN95 already supports a significant number of 200x features and more are being added.
IMO you attach too much significance to the Polyhedron speed tests and you are wrong to imply that we could easily match Intel for speed etc. if we simply put our minds to it.
If runtime speed is relevant and you can afford an Intel compiler then use FTN95 for development and switch to Intel for your release version but be aware that there may be other factors to consider before buying. |
|
| Back to top |
|
|
mecej4
Joined: 31 Oct 2006
Posts: 1925
|
| Posted: Sun Oct 16, 2022 9:25 am Post subject: |
|
|
Paul, re "If runtime speed is relevant and you can afford an Intel compiler then use FTN95 for development and switch to Intel for your release version but be aware that there may be other factors to consider before buying", please note that the Intel compilers (C and Fortran) and libraries (MKL, IPP, etc.) are now provided free to all users, on Windows, Linux and MacOS (Intel only).
The change from paid to free occurred a couple of years ago, and the product name was changed to OneAPI. Their C/C++ and Fortran compilers are transitioning to LLVM based products.
Customers who wish can purchase contracts for priority support.
Paul's advice "use FTN95 for development and switch to Intel for your release version" is good advice. Even if "release" includes "make production runs with big data sets for yourself". |
|
| Back to top |
|
|
PaulLaidler
Site Admin
Joined: 21 Feb 2005
Posts: 8302
Location: Salford, UK
|
| Posted: Sun Oct 16, 2022 9:38 am Post subject: |
|
|
| Yes. I was about to correct this error myself. |
|
| Back to top |
|
|
LitusSaxonicum
Joined: 23 Aug 2005
Posts: 2431
Location: Yateley, Hants, UK
|
| Posted: Sun Oct 16, 2022 10:36 am Post subject: |
|
|
The Polyhedron benchmarks are seductive, and no doubt Dan is right in saying that they have put users off FTN95. The problem is that the benchmark results are fake. Not fake in a deliberately misleading sense, but fake nonetheless.
The reason that I say so is that none of the test programs is the original, unadulterated, code as originally written, but is code generated after that original was run through code polishing software (CPS). All the examples are therefore examples of a particular style of programming. It only needs for the CPS to insert one or two constructs where FTN95 is, indeed, slow, and you get the results seen in the table. For someone who doesnt use that CPS, and doesnt use those constructs, the apparent slow-downs are simply not seen.
The evidence is clear from Mecej4s problem with SPREAD. If the CPS uses SPREAD a lot, then the benchmark figures would be the obvious result. Note that using the original style of programming, there wasnt such a slowdown.
There is another case where FTN95 might underperform at runtime, and that is where the programmer uses those slow constructs.
If Paul wants my advice, then it is to respond to the things that Mecej4 finds and address the issues that he has identified, even though for me, it doesnt matter at all.
The other issue is does it matter? Certainly, anything that requires extensive user interaction, for example using ClearWin+ for user input and drawing something, speed simply isnt an issue. Moreover, there is the matter of what is a useful speed improvement?
Eddie |
|
| Back to top |
|
|
DanRRight
Joined: 10 Mar 2008
Posts: 2952
Location: South Pole, Antarctica
|
| Posted: Mon Oct 17, 2022 5:44 am Post subject: |
|
|
Paul,
Older age Fortran users base slowly depleting, younger will avoid FTN95 due to such poor run-time results. Why bother with the switching compilers if new users can take Intel for free? Main reason why people chose Fortran (for example going from MATLAB) is because of stigma that it is superfast. And when they see black eye in speed of FTN95 in all benchmarks, no multicore capabilities and no promises that they will appear any time soon what do you think will happen?
Somehow all other compilers managed to be all in the same cohort, only FTN95 is way out of charts. The compilers marked with AP in this table use auto-parallelization, which of course is not easy to implement, but at least being in the middle of the table without AP and also to add OpenMP and MPI support are absolutely needed for youngsters to even look at anything besides Intel in present situation.
As to compilation speed, today i counted how long go my compilations with MAKE in gFortran for example. Yes, i am forced to use it or Intel because FTN95 is not supporting OpenMP, MPI and Fortran2008. Compilations mostly go for a half-a-second due partial compilation MAKE doing smartly and automatically. Computers became fast with that, who will care about split of a second? But have anyone tried gFortran debugger GDB ? It is like you returned back to Fortran4 in the middle of last century.
Mecej4,
what is "intel only"? Is AMD still out of luck? I tried oneAPI a year ago it did not work. Linux typically has all possible compilers available for free (specifically all supercomputers have anything you want). This is why i'd urge developers to fix this damn Polyhedron table ASAP in order to be at least in the middle of it. Your help here would be valuable i think.
Eddie,
i have older and new Polyhedron tests and even original author's code and checked this notorious slowest 499 seconds long benchmark mp_propeller_design, the only dressing was to make variables look like Fortran90 style instead of upper case Fortran77 and the line continuations were with the & at the end and beginning of lines. The tests for Polyhedron were SPECIFICALLY chosen to be real life programs, not fake artificial sh#t. This test, Google it - it's called PROP_DESIGN - the guy wrote working for airplane engine designs for major companies and you still can download it.
Anyway, was CPS dressing bad or not all compilers in this table were tested in equal conditions. Those who will see this table will care less was it dressed or not. By the way can you point me on good CPS software? I got stuck with one Fortran77 program which will kill me with its only 72 char per line 
Last edited by DanRRight on Mon Oct 17, 2022 7:30 am; edited 2 times in total |
|
| Back to top |
|
|
mecej4
Joined: 31 Oct 2006
Posts: 1925
|
| Posted: Mon Oct 17, 2022 6:51 am Post subject: |
|
|
Dan, the context of "Intel only" is that Intel compilers do not produce native ARM or PPC code.
You can use Intel compilers on Apple Mx, but only through Apple's Rosetta emulation. As far as I know, Apple did not use processors made by AMD/VIA/Elbrus/...
Some of the Polyhedron benchmarks were polished using VAST. Look for "Pacific Sierra" in the comments in the code. Most were polished using Polyhedron's own SPAG. There is no instance of SPREAD in any of the source files of the benchmark.
Last edited by mecej4 on Tue Oct 18, 2022 2:13 am; edited 1 time in total |
|
| Back to top |
|
|
PaulLaidler
Site Admin
Joined: 21 Feb 2005
Posts: 8302
Location: Salford, UK
|
| Posted: Mon Oct 17, 2022 3:40 pm Post subject: |
|
|
mecej4
Thank you for your latest post which is helpful. |
|
| Back to top |
|
|
PaulLaidler
Site Admin
Joined: 21 Feb 2005
Posts: 8302
Location: Salford, UK
|
| Posted: Mon Oct 17, 2022 3:44 pm Post subject: |
|
|
| Please note that this thread is now terminated and further replies may be deleted. |
|
| Back to top |
|
|
|
|
You cannot post new topics in this forum
You cannot reply to topics in this forum
You cannot edit your posts in this forum
You cannot delete your posts in this forum
You cannot vote in polls in this forum
|
Powered by phpBB © 2001, 2005 phpBB Group
|

